
Chapter 11
Data Transformations
By Kiran PV
This chapter covers more advanced statistical concepts than some of the others but we wanted to include a brief introduction to data transformations in case you encounter them. If you need to do your own transformation, check out the resources in our Appendix for additional tips.
When you take a digital photo, sometimes the picture comes out in a way that makes certain features hard to see. Maybe the colors are too dark or too light, the photo is blurry, or the objects in the image are too small and you want to zoom in on them. You can pop the photo into something like Instagram or Photoshop, tweak it, apply a filter or two, and transform the picture so it’s much clearer and easier to understand.
Sometimes we need to transform data, too. You might get a set of data where, if you visualize it as is, there will be parts that are difficult to see. Also, if you’re going to do statistical testing of your data, many common tests make specific assumptions about the distribution of the data (e.g. that the data are normally distributed). In the real world, we often come across data that don’t meet these assumptions. Data transformations are one way to handle both of these problems. Here, we’ll talk about some of the more common transformations so that when you encounter these terms in the future you’ll have an idea what was done to the data.
Data transformations are one of the common manipulation procedures which can reveal features hidden in the data that are not observable in their original form. We can transform the distribution of data to make it easier to see and so that any required assumptions of statistical tests are met. We usually do this by replacing one variable with a mathematical function operating on that variable. For example, you could replace a variable x by the logarithm of x or by square root of x.
Never perform the transform directly on your original data! Either create an additional column to hold the new values for each variable you’re transforming or make a copy of your entire dataset.
Normal Distribution and Skewness in Data
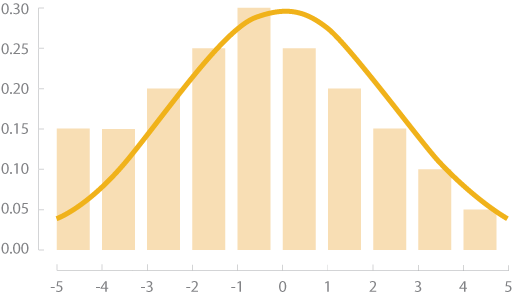
One of the most frequently-encountered assumptions of statistical tests is that data should be normally distributed. You may have heard of the normal distribution referred to as a “bell curve” before; this is because a normal distribution takes the shape of a bell, with the data spread around a central value. Some of the data examples that commonly follow a normal distribution are related to human measurements such as height, weight, life span, and scores on IQ tests.
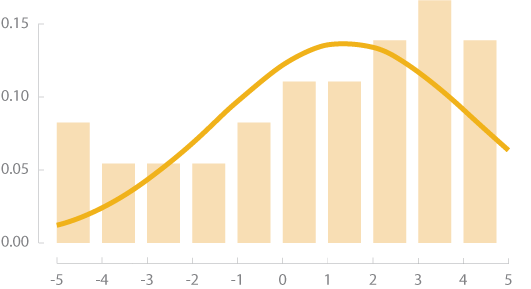
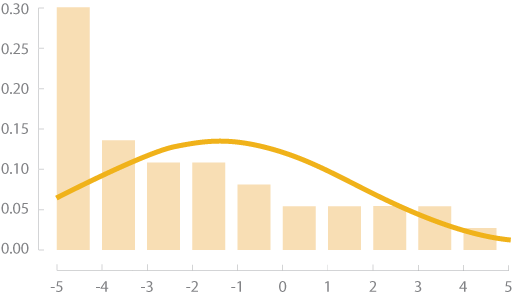
Unlike a normal distribution, which is symmetric around the mean value, skewed data tend to have more observations either to left side or to right side. Right skewed data have a long tail that extends to right whereas left skewed data will have a long tail extending to the left of the mean value. When data are very skewed, it can be hard to see the extreme values in a visualization. If you notice that your data distribution is skewed, you might consider transforming it if you’re doing statistical testing or if the data are difficult to visualize in their original state.
Normal Distribution
Left Skew
Right Skew
Understanding Transformations Using Sample Data
Let’s use the population and land area of the 50 US states from 2012 to see how transformations work on actual data. The first step in transformation is to evaluate the distribution of the data. Then you can decide what transformation is appropriate (if one is needed). We can start by constructing a histogram of the population data and a scatterplot of the population-area data to get a better sense of how they’re distributed.
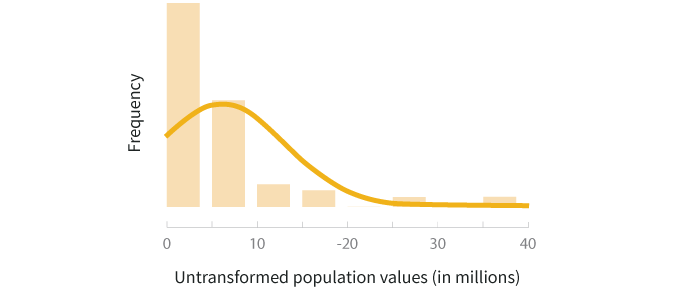
The histogram above shows that the distribution of population values is right skewed. This is reasonable to expect because the majority of states’ populations lie in the range of 1-10 million. If we want to do statistical testing that relies on a normal distribution assumption, these data will need to be transformed.
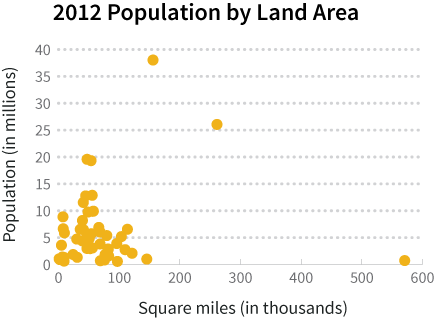
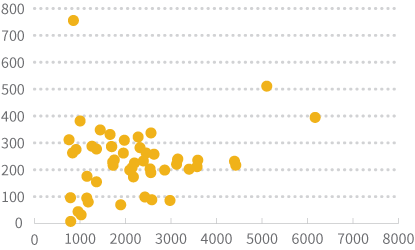
In the scatter plot above, you can see that most of the data points are clustered in the bottom left corner of the graph, making it hard to see how population and land area are related. We can’t just scale the graph differently to “zoom in” on that corner because we’d knock California and Alaska off the chart. We can, however, use transformations to help make the data easier to view.
There are many transformation methods that can be applied in either of these situations, but let’s look at a couple of the common ones to see how they can affect both a visualization and the shape of a distribution.
Log Transform
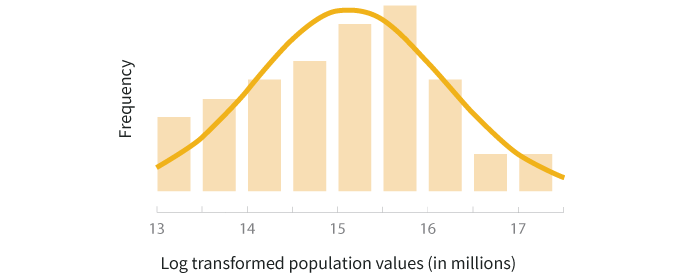
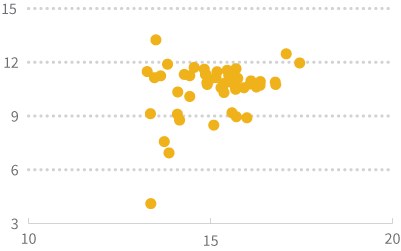
To do a logarithmic transformation, you calculate the log of each value in the dataset and use those transformed values rather than your raw data. Log transforms tend to have a major effect on distribution shape, and in visualizations can bring extreme outliers closer to the rest of the data so graphs aren’t stretched out as much. You can either use natural logs (ln) or logs with base 10. The graphs below show the histogram of population data after a natural log transformation is applied and what the scatterplot looks like if you use a natural log transformation on both the population and land area variables.
Square Root Transform
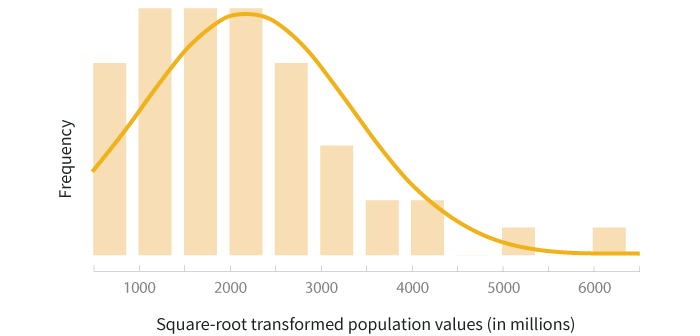
The square root transformation uses the square root of each value instead of the log, and has a more moderate effect on the distribution shape. The two graphs below show the histogram of population data and the scatterplot of population by land area, both after square root transformation is applied .
Choosing the Right Transform
As you develop a better understanding of different transformation methods, you might wonder how to pick between them. The answer to this question is not straightforward and although there are formal statistical methods for selecting a transformation, we often need to use trial-and-error combined with knowledge of different transformations. A general strategy is to apply some of the most frequently used transforms such as log, square root, square, reciprocal, and cube root, and then choose the best one after observing the results.
Looking at the transformed histograms above, the log transformed data seems to be a better fit to the normal distribution while the square root transformed data still carries the right skew. In this example, if you’re doing a statistical test that has assumes the data are normally distributed, the log transformation would be a better method to use than the square root transformation.
On the other hand, if your primary purpose in the example above is to visualize the relationship between state population and land area, the square root transformation does a better job of spreading out the data and making it easier to view than the log transformation.
Common Transformations
| Method | Math Operation | Good for: | Bad for: |
|---|---|---|---|
| Log | ln(x) log10(x) |
Right skewed data log10(x) is especially good at handling higher order powers of 10 (e.g. 1000, 100000) |
Zero values Negative values |
| Square root | √x | Right skewed data | Negative values |
| Square | x2 | Left skewed data | Negative values |
| Cube root | x1/3 | Right skewed data Negative values |
Not as effective at normalizing as log transform |
| Reciprocal | 1/x | Making small values bigger and big values smaller | Zero values Negative values |
Caveats about Transformation
Since data transformation methods involve the application of a mathematical function to your data, you need to be careful when reporting or interpreting any insights derived from the transformed data because a transformation changes the unit of the data. For example, when we apply a logarithmic function to a population variable, the unit of measurement becomes the log of the population. When you’re sharing results, your audience may assume that the calculated numbers or visualizations they’re seeing are based on raw data, so if the values have been transformed, you should clearly communicate what transformation was used, as well as what units the data are being displayed in.
If you use transformed data to calculate statistical values like means, you should back-transform the final results and report them in their original units. To back-transform, you just do the opposite of the mathematical function you used in the first place. For example, if you did a square root transformation, you would back-transform by squaring your end result.
You may not see transforms every day, but when you do, it’s helpful to know why they were used and how they affect your data. It’s important to be able to see different parts of the picture when working with data, and transformations give you another tool to help you do just that!